이 문제의 경우 그리디와 비트 마스킹 문제이다 처음에는 while문으로 코드를 작성했으나 해당 문제를 해결 하려했으나 실패 했다. 이에 비트 마스킹을 사용해서 문제를 풀어야 함을 깨달았다. 이 문제를 풀기 위한 생각은
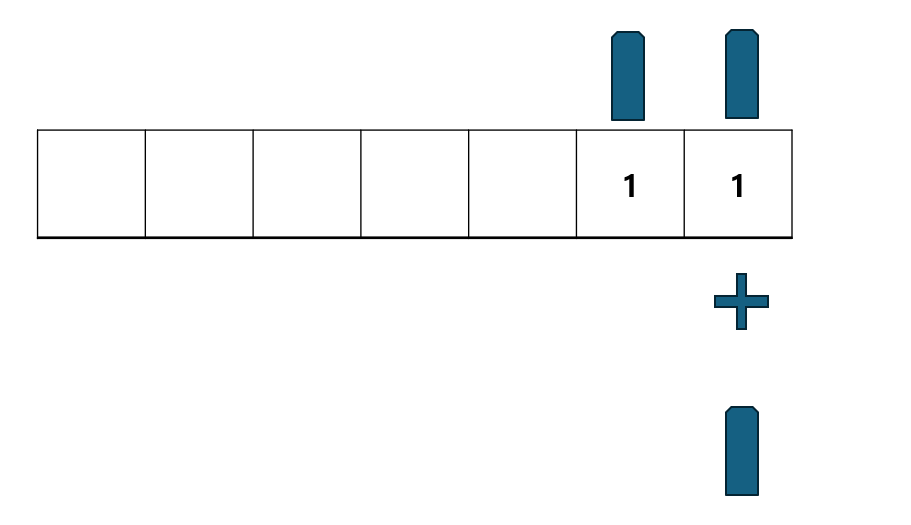
3리터짜리 물병을 생각해 보면 2리터 물병 하나 1리터 물병이 있다고 가정 하자. 얘를 물병 한개짜리를 만드는 방법은 1리터짜리 물병을 하나더해서 2리터짜리를 만든후 4리터 물병을 만드는 방법이다
즉 이문제를 풀기 위해서는 가장 작은 물병들을 계속 그다음 큰 물병들로 만들면서 진행 해야한다 자 대표적인 예로 2번째 테스트 케이스를 예시로 생각해봅시다
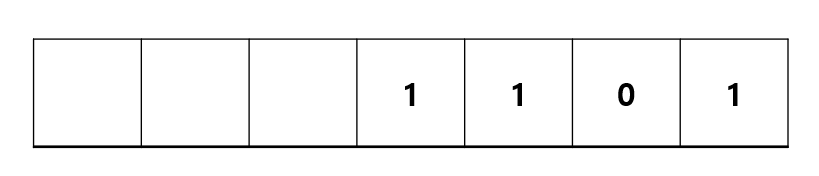
이 문제의 경우 0번째 칸에 있는 1리터짜리 물병을 일단 큰물병으로 만들어보자 1+1 해서 2리터로 만든다 그 후 최소 물병과 다른 물병의 갯수를 저장해놓고 일단 계속 가장 작은 물병을 다음 큰 물병으로 변경시켜 가면서 물병을 합치면서 크기를 늘리면서 갯수를 줄이는 로직이다 그후 최소 물병의 갯수를 만족하면 로직진행을 끝내면 된다
#include<bitset>
#include<iostream>
using namespace std;
int main() {
int n, k;
int ans=0;
cin >> n >> k;
while (true) {
int temp = n;
// 현재 1을 못만났다는 의미
int firstOnidx = -1;
// 내가 가지고 있는 물병의 갯수
int cnt=0;
// 내가 비교하려는 인덱스의 번호
int idx = 0;
//현재 물병의 수를 세는 로직
while (temp) {
if (temp & 1) {
if (firstOnidx == -1)
firstOnidx = idx;
cnt++;
}
idx++;
//다음 번째 인덱스를 비교하기 위해 오른쪽으로 1칸 이동
temp >>= 1;
}
//
if (cnt <= k) {
break;
}
else {
//가장 작은 양이 담겨져 있는 물병을 합쳐서 다음 크기의 물병을 만들기 위함 반복하다보면 원래있던 더큰 크기의 물병과 합쳐지면서 크기가 줄어듬
n += (1 << firstOnidx);
//산 물병의 갯수 크기2짜리 물병은 1개짜리 물병 2개 합친것
ans += (1 << firstOnidx);
}
}
cout << ans;
}
이 문제의 경우 그리디 문제이다 이 문제의 경우 Priority Queue로 풀면 쉽게 풀리는 문제였다. 일단 나는 이 문제를 보고 냅색문제 와 비슷 하다고 생각했다.
일단 나는 이문제의 숙제의 중요도를 숙제의 점수 라고 생각 했다 이에 우선순위 큐에 과제를 끝냈을 때의 점수가 가장 높은것들 순으로 나열 시켰다.
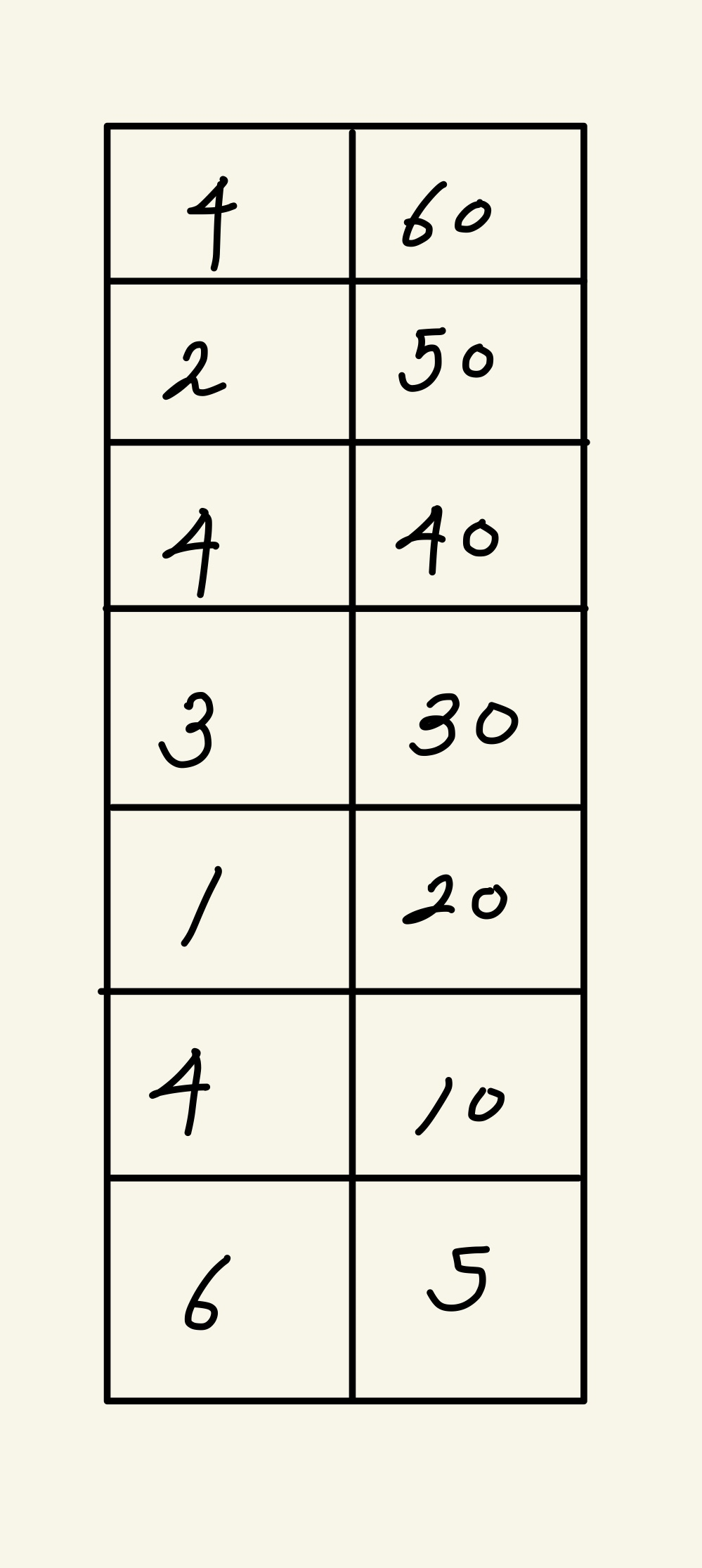
7
4 60
4 40
1 20
2 50
3 30
4 10
6 5
우리의 테스트 케이슬 중요도 즉 과제를 맞췄을 때의 점수를 해당로직대로 내림차순 정렬 하게 되면 아래 그림 처럼 된다
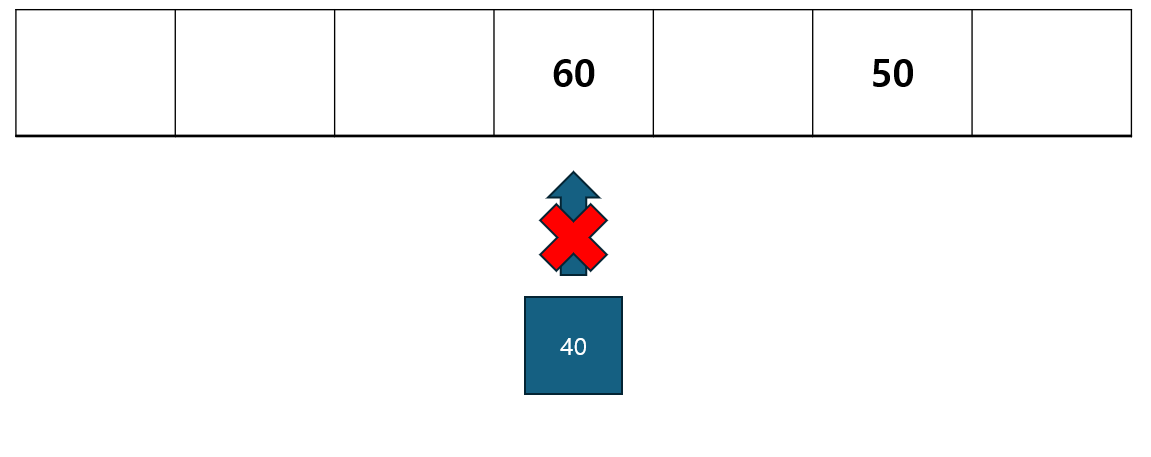
우리가 실제로 과제를 한다 생각 해 보자 우리는 당연히 가장 중요한걸 될 수 있는 한 최대한 미룰 것이다 즉 첫번째 4,60은 아직 4일 차에 내가 할 일이 없으므로 60에 중요도를 가진 과제를 한다.
그후 오는 2,50은 아직 2일차에 아무일도 없으므로 50에 일을 한다
그 후 4,40의 일은 4일 안에만 하면 되나 4일차에는 60의 일이 있으므로 4일보다 앞에 배정한다 그래서 3일 차에 40의 일을 한다
그후 3,30은 이미 3일차에 40의 일을 하였으니 3일안에 내가 할수 있는 요일은 1일차 밖에 없다 이에 30의 일은 1일 차에 한다
그후 1,20의 일은 이미 1일차에 30의 일을 하니 하지 않는다
그후 4,10의 일도 이미 4일 안에 진행 하는 일들은 다 중요도 가 높으므로 진행 하지않는다 그후 6,5는 6일차는 비어 있으므로 넣는다
즉 이문제의 풀이는 날짜를 최대한 미루데 중요한거를 우선 해서 리스트에 넣어야 한다 이에 만약 내가 4,40의 일을 한다고 가정했을 때 지금 업무를 완료했을 때의점수순으로 나열했기에 후에 나보다 낮은 일수가 나온다고 해도 점수가 높지 않고 일수도 낮고 점수도 낮은게 나올 수가 없으므로 빈공간에 채워주는 식으로 로직을 진행해야 한다
#include<iostream>
#include<queue>
using namespace std;
int day[1001] = {};
struct Compare {
bool operator()(pair<int, int> const& p1, pair<int, int> const& p2) {
return p1.second < p2.second;
}
};
priority_queue<pair<int,int>, vector<pair<int,int>>, Compare> pq;
int main() {
int N;
cin >> N;
int num1, num2;
int maxIdx=0;
int result = 0;
for (int i = 0; i < N; i++) {
cin >> num1 >> num2;
if (num1 > maxIdx) {
maxIdx = num1;
}
pq.push({ num1,num2 });
}
while (!pq.empty()) {
int x, y;
x = pq.top().first;
y = pq.top().second;
pq.pop();
if (day[x]== 0) {
day[x] = y;
}
else {
for (int i = x - 1; i > 0; i--) {
if (day[i] == 0) {
day[i] = y;
break;
}
}
}
}
for (int i = maxIdx; i > 0; i--) {
result += day[i];
}
cout << result;
}
이 문제의 경우 DP중에 LCS라는 것에 공부해보았으면 풀 수 있는 문제 였다 처음 보고 나서 부분 순서가 아닌 부분수열로 보아서 틀렸었다 이에 LCS 알고리즘에 대해 공부한 푸니 그리 어렵지 않은 문제였다
#include <iostream>
#include <cstring>
using namespace std;
#define max(a, b) (a > b ? a : b)
int LCS[1002][1002];
char str[1003];
char str2[1003];
int main()
{
cin >> str >> str2;
int i, j;
i = 1;
while (i <= strlen(str))
{
j = 1;
while (j <= strlen(str2))
{
if (str2[j - 1] == str[i - 1])
{
LCS[i][j] = LCS[i - 1][j - 1] + 1;
}
else
{
LCS[i][j] = max(LCS[i - 1][j], LCS[i][j - 1]);
}
j++;
}
i++;
}
printf("%d", LCS[i - 1][j - 1]);
}
맨 처음
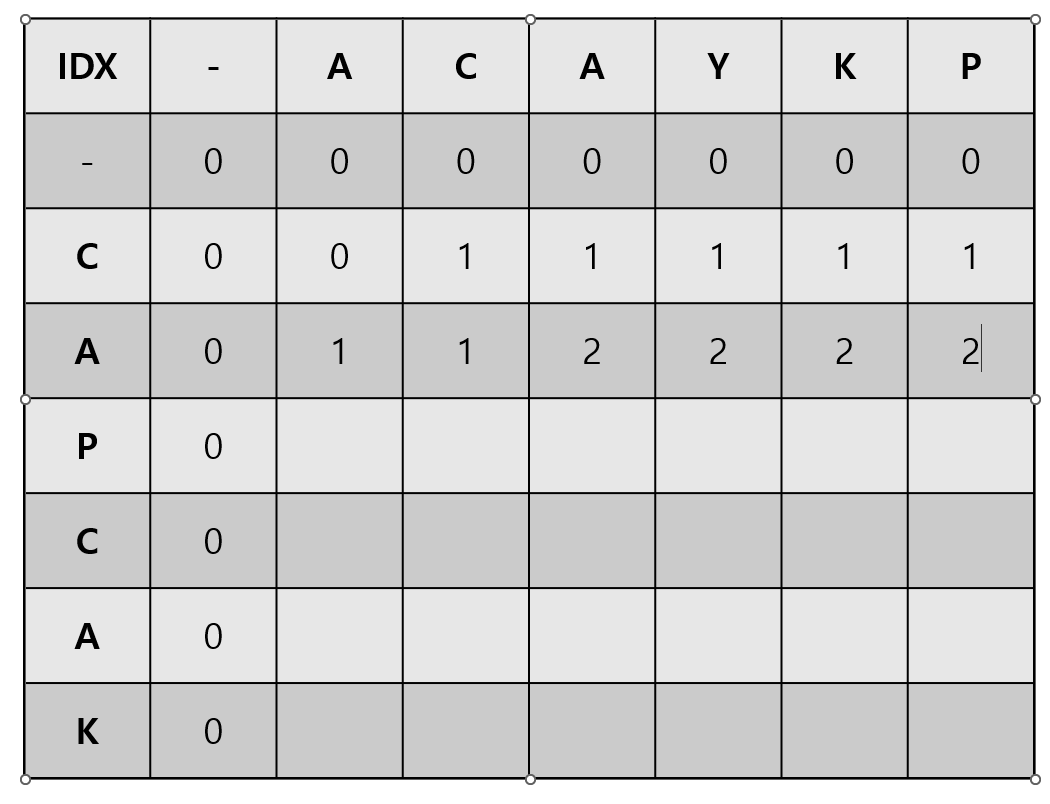
아래 와 같은 표를 만들준다 만들어 주게 되면 7X7 배열이 될텐데 이는 비교하지 않았을 때 에 대한 값 0을 넣어주기 위함이다.
이에 우리가 각 행 마다 채워넣어줄 것은 각각 행까지의 문자들을 열까지의 문자들과 비교했을 때 최대로 나오는 부분 수열의 크기를 넣어줘야한다 이를 바탕으로 다음 수열의 최댓값을 찾을 것이다
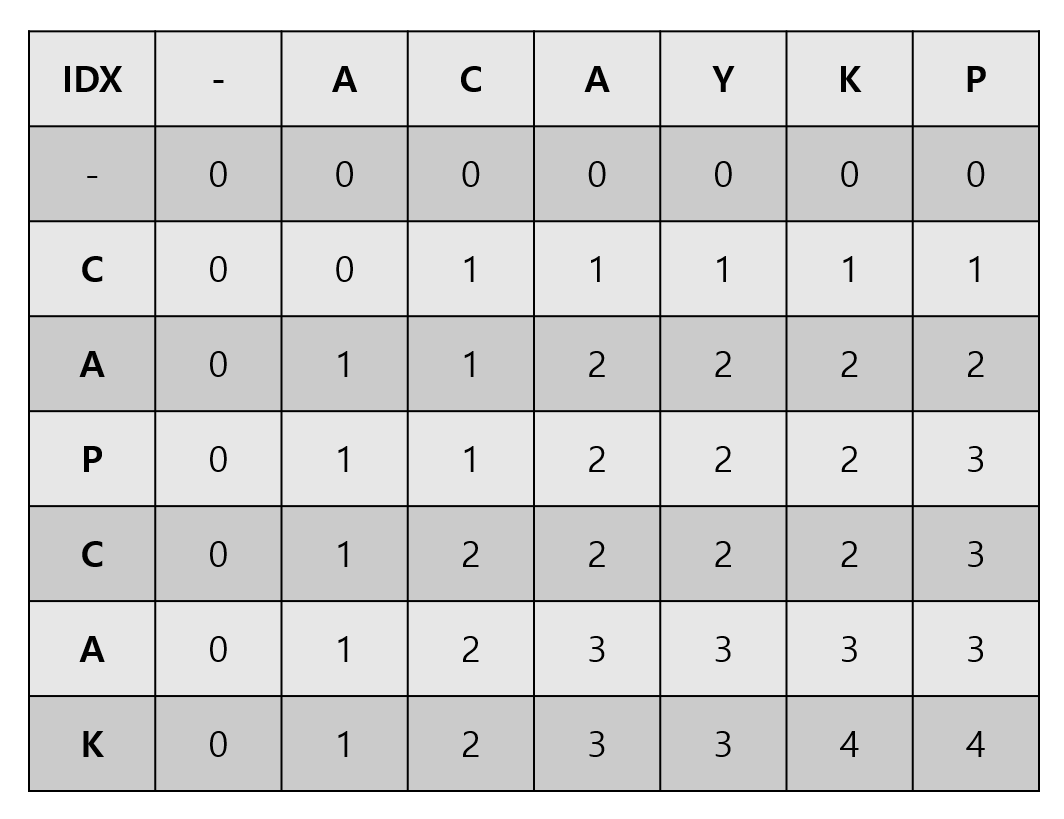
즉 C를 열들의 문자와 비교한다 1행 1열이 0인이유는 C를 A까지 비교했을떄 나오는 부분수열이 없기 떄문이다 그후 C를 A C라는 문자열과 비교했을 때 부분수열로 나온것은 C이니 1 지금 집합 C에서의 부분수열이 1밖에 나올수 없으므로 1만채워주게 된다
그 후 두번째 줄은 C A에서의 부분수열값과 A의 부분수열값을 비교해주게 되는데 C A와 A는 하나의 부분수열 만 공유한다 C A와 A C 도마찬가지이다 C혹은 A만을 공유하기에 1이다 단 이제 C A와 A C A를 비교해주게 되면 현재 C A로 부분수열이 만들어진다 이것은 즉이것은 C만을 비교했을 때 이미 부분수열이 1이었고 그다음 A를 비교했을 때 이부분이 현재 같으므로 이전에 가져왔던 값에 +1을 해주게 된다 그림을 완성 하게 되면
이런식으로 된다 즉 이 문제를 푸는 핵심은 x축으로의 문자열 과 y축으로 문자열을 비교해서 즉 y 인덱스 까지의 수열에서 행의 문자열들과 몇개가 유사한지를 찾는 것이다 이 부분에서 사용되어야 할게 나의 이전에 문자이다 . 예로 A C A 와 C A를 비교했다고 가정하자 이미 C를 검사했을 때 x축의 C 의 이후 문자들에서는 무조건 1개의 부분수열이 발생한다는 의미이고 C A와 검사했을 때 C까지 이미 1인 부분수열이 있었으므로 A를 만났을 때 A의 이전까지의 최대 부분수열의 갯수와 지금 일치한 대각선의 값이 +1되게 하여 증가시키는 것이다 즉 A C 와 C를 비교했을 때 이미 1개의 부분수열이 존재함으로 A C A 와 C A 를 비교했을때 +1을 해주게 되는 것이
결국에 이식의 점화식은
LCS[i][j] = LCS[i - 1][j - 1] + 1;
LCS[i][j] = max(LCS[i - 1][j], LCS[i][j - 1]);
이렇게 2개가 되는데 같은 문자를 발견했을 때는 나의 이전 문자까지 비교했을 때의 최대 부분수열의 구성요소 갯수 +1을 해야함으로 i-1과 j-1인덱스의 값에서 +1을 증가시킨다
반대로 틀릴경우에는 즉 y축에서의 나의 이전의 값을 가져오거나 나까지 비교하기전에 최대 부분수열의 인덱스를 가져오게 된다
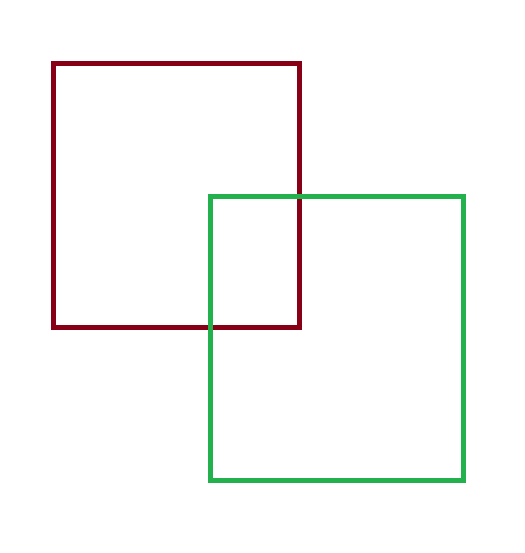
우리가 충돌 알고리즘을 사용할 때 가장 간단 한 버전의 충돌 알고리즘이다 AABB 알고리즘이란 특정 좌표계에서 사각형혹은 직육면체 형태의 범위에 대한 충돌을 검증 할 때 사용한다
이렇게 4각형이 2개 겹쳐 있을 때 수식을 이용해서 충돌 여부를 구하는 방식이다 이방식은 3차원에서도 비슷하게 사용이 가능하다. 근데 유니티에서 제공하는 함수를 사용 하면 offset 즉 범위 확장이 불가능 했었다. 이에 해당 기능을 직접 구현했어야 했다.
구현하면서 시행착오 겪었던 내용은 Bound의 Min값과 Max값을 계속 가져왔는데 이 좌표계가 매우 이상했다 분명 다른 위치에 있는데 같은좌표를 반화하는것을 보고 Bound의 Min값과 Max값이 local position임을 깨달았다. 이에 해당 사항들을 world position으로 변경 해줘야 한다 이에 TrasnformPorint 함수를 사용해준다
이 문제는 간단한 문제인줄 알고 건드렸다가 2시간을 날릴 정도로 고생한 문제이다 일단 이 문제의경우 딱 봤을 때 BFS를 사용하는거는 확실 해 보이지만 매번 시추할 때 마다 BFS를 돌리면 효율성 검사에서 점수가 떨어지게 된다 이에 이문제는 BFS를 이용해서 뽑아낸 데이터를 어떤 자료 구조에 넣어 사용하는 지가 매우 중요한 문제이다
#include <string>
#include <queue>
#include <vector>
#include <map>
#include <set>
#include <algorithm>
using namespace std;
int directionX[4] = { 1, 0, -1, 0 };
int directionY[4] = { 0, 1, 0, -1 };
int isVisited[501][501] = { 0, };
map<int, int> sizeOfOil;
int sizeOfLandX;
int sizeOfLandY;
int areaNum = 1;
vector<vector<int>> oilMap;
void BFS(int startX, int startY ) {
int tmp = 0;
queue<pair<int, int>> q;
q.push({ startX, startY });
oilMap[startX][startY] = areaNum;
isVisited[startX][startY] = 1;
while (!q.empty()) {
int x = q.front().first;
int y = q.front().second;
tmp++;
q.pop();
for (int i = 0; i < 4; i++) {
int nextX = x + directionX[i];
int nextY = y + directionY[i];
if (nextX >= 0 && nextX < sizeOfLandX && nextY >= 0 && nextY < sizeOfLandY && isVisited[nextX][nextY] == false && oilMap[nextX][nextY]>0) {
oilMap[nextX][nextY] = areaNum;
isVisited[nextX][nextY] = 1;
q.push({ nextX,nextY });
}
}
}
sizeOfOil[areaNum] = tmp;
areaNum++;
}
int solution(vector<vector<int>> land) {
int answer = 0;
oilMap = land;
sizeOfLandX = land.size(); //열의 길이
sizeOfLandY = land[0].size(); //행의 길이
for (int i = 0; i < sizeOfLandX; i++) {
for (int j = 0; j < sizeOfLandY; j++) {
if (isVisited[i][j] == false && land[i][j] == 1) {
BFS(i, j);
}
}
}
for (int j = 0; j < sizeOfLandY; j++) {
set<int> oilSet;
int sumOfOil=0;
for (int i = 0; i < sizeOfLandX; i++) {
oilSet.insert(oilMap[i][j]);
}
set<int>::iterator iter;
for (auto it : oilSet) {
sumOfOil += sizeOfOil[it];
}
answer = max(answer, sumOfOil);
}
return answer;
}
일단 이 문제의 경우 내가 블로그에 기존에 올렸던 BFS보다 간단 하다 원래는 Direction을 일일히 내가 정해줬었는데 이를 배열에 넣어 간단하게 보이게 했다. 코드 가독성이 올라가니 확실히 디버깅 효율이 올라갔다
자 일단 이문제의 핵심로직은 BFS로 구해놓은 영역의 유전의 크기를 영역별로 들고 있어야 한다 이를 위해 위 코드에
void BFS(int startX, int startY ) {
int tmp = 0;
queue<pair<int, int>> q;
q.push({ startX, startY });
oilMap[startX][startY] = areaNum;
isVisited[startX][startY] = 1;
while (!q.empty()) {
int x = q.front().first;
int y = q.front().second;
tmp++;
q.pop();
for (int i = 0; i < 4; i++) {
int nextX = x + directionX[i];
int nextY = y + directionY[i];
if (nextX >= 0 && nextX < sizeOfLandX && nextY >= 0 && nextY < sizeOfLandY && isVisited[nextX][nextY] == false && oilMap[nextX][nextY]>0) {
oilMap[nextX][nextY] = areaNum;
isVisited[nextX][nextY] = 1;
q.push({ nextX,nextY });
}
}
}
sizeOfOil[areaNum] = tmp;
areaNum++;
}
BFS 부분에서sizeOfOil에 저장해 주었다 여기서 sizeOfOil은 맵 자료형이다 맵자료형은 map<int,int>이렇게 사용했을 때 맨앞에 오는 값은 Key로서 두번쨰 오는 값은 value로 써 작용합니다. 즉 map<key,value> 의 형태로 각각의 해당하는 자료형을 넣어주면 됩니다 .
이 문제에서는 Map의 저장해놓은 데이터를 순환하여 찾아와야 하기 때문에
for (auto iter = m.begin() ; iter != m.end(); iter++)
{
cout << iter->first << " " << iter->second << endl;
}
cout << endl;
의 형태와
for (auto iter : m) {
cout << iter.first << " " << iter.second << endl;
}
의 형태의 두가지 형태로 map을 순환 할 수 있습니다. 이에 필자는 두번째 형태로 사용하였습니다.
이렇게 Map형태로 저장해놓은 데이터에서 우리는 land 배열에 새로줄에서 만나는 areaNum들을 set에 넣어줍니다. Set은 마찬가지로 중복되는 자료를 넣으면 넣지 않기 때문에 areaNum을 최대 1번씩만 넣을 수 있습니다 이에 set.insert를 이용해서 각 세로줄에 있는 유전의 areaNum을 넣습니다.
그후 이를 순회하면서 areaNum을 통해 세로줄에 있는 해당 유전에 크기를 더하여 최대값을 출력합니다